scrapy
Scrapy
Scrapy的简单使用
创建项目:scrapy startproject xxx(爬虫名)
进入项目:cd xxx #进入某个文件夹下
创建爬虫:scrapy genspider xxx(爬虫名) xxx.com (爬取域)
生成文件:scrapy crawl xxx -o xxx.json (生成某种类型的文件)
运行爬虫:scrapy crawl XXX
列出所有爬虫:scrapy list
获得配置信息:scrapy settings [options]
1 | scrapy startproject xxx(爬虫名) |
Scrapy的整体架构和组成
Scrapy框架的整体架构和组成
官方Scrapy的架构图
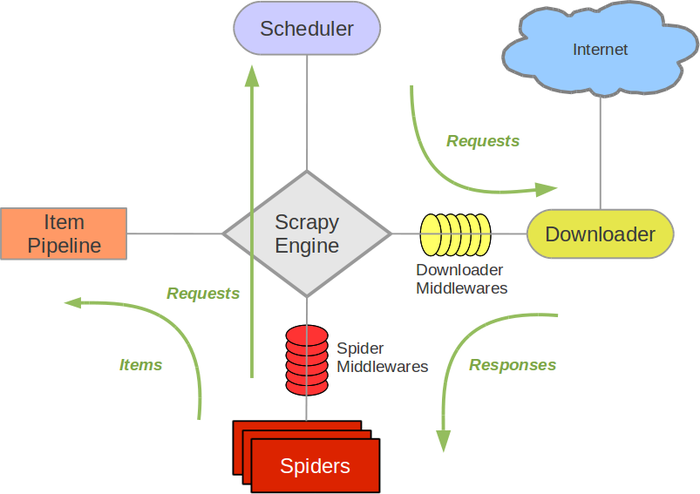
图中绿色的是数据的流向
我们看到图里有这么几个东西,分别是
Spiders:爬虫,定义了爬取的逻辑和网页内容的解析规则,主要负责解析响应并生成结果和新的请求
Engine:引擎,处理整个系统的数据流处理,出发事物,框架的核心。
Scheduler:调度器,接受引擎发过来的请求,并将其加入队列中,在引擎再次请求时将请求提供给引擎
Downloader:下载器,下载网页内容,并将下载内容返回给spider
ItemPipeline:项目管道,负责处理spider从网页中抽取的数据,主要是负责清洗,验证和向数据库中存储数据
Downloader Middlewares:下载中间件,是处于Scrapy的Request和Requesponse之间的处理模块
Spider Middlewares:spider中间件,位于引擎和spider之间的框架,主要处理spider输入的响应和输出的结果及新的请求middlewares.py里实现
是不感觉东西很多,很乱,有点懵!没关系,框架之所以是框架因为确实很简单
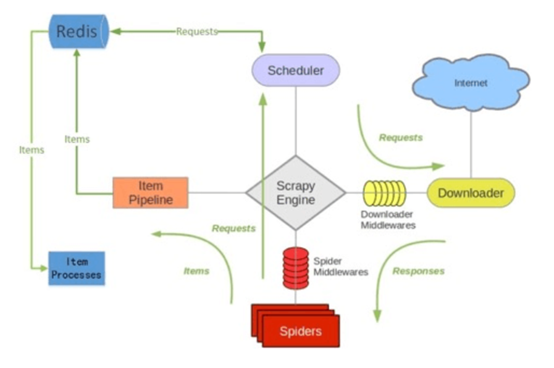
我们再来看下面的这张图!你就懂了!

- 最后我们来顺一下scrapy框架的整体执行流程:
1.spider的yeild将request发送给engine
2.engine对request不做任何处理发送给scheduler
3.scheduler,生成request交给engine
4.engine拿到request,通过middleware发送给downloader
5.downloader在\获取到response之后,又经过middleware发送给engine
6.engine获取到response之后,返回给spider,spider的parse()方法对获取到的response进行处理,解析出items或者requests
7.将解析出来的items或者requests发送给engine
8.engine获取到items或者requests,将items发送给ItemPipeline,将requests发送给scheduler(ps,只有调度器中不存在request时,程序才停止,及时请求失败scrapy也会重新进行请求)
Scrapy的中间件详解
Scrapy框架的安装
1 | # update pip |
scrapy创建项目
1 | #创建Demo1的项目 |
scrapy流程
pipeline介绍
logging模块
debug信息
scrapyShell
scrapyettings和管道
crawlspider爬虫
1 | scrapy genspider -t crawl example example.com |
url拼接
1 | import scrapy |
携带cooke登陆
下载中间件
scrapy 模拟登陆
scrapy_redis
https://www.cnblogs.com/Mint-diary/p/9728435.html
内容持续更新中….
 wechat
wechat alipay
alipay


